Myths about /dev/urandom¶
There are a few things about /dev/urandom and /dev/random that are repeated again and again. Still they are false.
By the way
I'm mostly talking about reasonably recent Linux systems, not other UNIX-like systems.
/dev/urandom is insecure. Always use /dev/random for cryptographic purposes.
Fact: /dev/urandom is the preferred source of cryptographic randomness on UNIX-like systems.
/dev/urandom is a pseudo random number generator, a PRNG, while /dev/random is a “true” random number generator.
Fact: Both /dev/urandom and /dev/random are using the exact same CSPRNG (a cryptographically secure pseudorandom number generator). They only differ in very few ways that have nothing to do with “true” randomness.
/dev/random is unambiguously the better choice for cryptography. Even if /dev/urandom were comparably secure, there's no reason to choose the latter.
Fact: /dev/random has a very nasty problem: it blocks.
But that's good! /dev/random gives out exactly as much randomness as it has entropy in its pool. /dev/urandom will give you insecure random numbers, even though it has long run out of entropy.
Fact: No. Even disregarding issues like availability and subsequent manipulation by users, the issue of entropy “running low” is a straw man. About 256 bits of entropy are enough to get computationally secure numbers for a long, long time.
And the fun only starts here: how does /dev/random know how much entropy there is available to give out? Stay tuned!
But cryptographers always talk about constant re-seeding. Doesn't that contradict your last point?
Fact: You got me! Kind of. It is true, the random number generator is constantly re-seeded using whatever entropy the system can lay its hands on. But that has (partly) other reasons.
Look, I don't claim that injecting entropy is bad. It's good. I just claim that it's bad to block when the entropy estimate is low.
That's all good and nice, but even the man page for /dev/(u)random contradicts you! Does anyone who knows about this stuff actually agree with you?
Fact: No, it really doesn't. It seems to imply that /dev/urandom is insecure for cryptographic use, unless you really understand all that cryptographic jargon.
The man page does recommend the use of /dev/random in some cases (it doesn't hurt, in my opinion, but is not strictly necessary), but it also recommends /dev/urandom as the device to use for “normal” cryptographic use.
And while appeal to authority is usually nothing to be proud of, in cryptographic issues you're generally right to be careful and try to get the opinion of a domain expert.
And yes, quite a few experts share my view that /dev/urandom is the go-to solution for your random number needs in a cryptography context on UNIX-like systems. Obviously, their opinions influenced mine, not the other way around.
Hard to believe, right? I must certainly be wrong! Well, read on and let me try to convince you.
I tried to keep it out, but I fear there are two preliminaries to be taken care of, before we can really tackle all those points.
Namely, what is randomness, or better: what kind of randomness am I talking about here?
And, even more important, I'm really not being condescending. I have written this document to have a thing to point to, when this discussion comes up again. More than 140 characters. Without repeating myself again and again. Being able to hone the writing and the arguments itself, benefitting many discussions in many venues.
And I'm certainly willing to hear differing opinions. I'm just saying that it won't be enough to state that /dev/urandom is bad. You need to identify the points you're disagreeing with and engage them.
You're saying I'm stupid!¶
Emphatically no!
Actually, I used to believe that /dev/urandom was insecure myself, a few years ago. And it's something you and I almost had to believe, because all those highly respected people on Usenet, in web forums and today on Twitter told us. Even the man page seems to say so. Who were we to dismiss their convincing argument about “entropy running low”?
This misconception isn't so rampant because people are stupid, it is because with a little knowledge about cryptography (namely some vague idea what entropy is) it's very easy to be convinced of it. Intuition almost forces us there. Unfortunately, intuition is often wrong in cryptography. So it is here.
True randomness¶
What does it mean for random numbers to be “truly random”?
I don't want to dive into that issue too deep, because it quickly gets philosophical. Discussions have been known to unravel quickly, because everyone can wax about their favorite model of randomness, without paying attention to anyone else. Or even making himself understood.
I believe that the “gold standard” for “true randomness” are quantum effects. Observe a photon pass through a semi-transparent mirror. Or not. Observe some radioactive material emit alpha particles. It's the best idea we have when it comes to randomness in the world. Other people might reasonably believe that those effects aren't truly random. Or even that there is no randomness in the world at all. Let a million flowers bloom.
Cryptographers often circumvent this philosophical debate by disregarding what it means for randomness to be “true”. They care about unpredictability. As long as nobody can get any information about the next random number, we're fine. And when you're talking about random numbers as a prerequisite in using cryptography, that's what you should aim for, in my opinion.
Anyway, I don't care much about those “philosophically secure” random numbers, as I like to think of your “true” random numbers.
Two kinds of security, one that matters¶
But let's assume you've obtained those “true” random numbers. What are you going to do with them?
You print them out, frame them and hang them on your living-room wall, to revel in the beauty of a quantum universe? That's great, and I certainly understand.
Wait, what? You're using them? For cryptographic purposes? Well, that spoils everything, because now things get a bit ugly.
You see, your truly-random, quantum effect blessed random numbers are put into some less respectable, real-world tarnished algorithms.
Because almost all of the cryptographic algorithms we use do not hold up to information-theoretic security. They can “only” offer computational security. The two exceptions that come to my mind are Shamir's Secret Sharing and the One-time pad. And while the first one may be a valid counterpoint (if you actually intend to use it), the latter is utterly impractical.
But all those algorithms you know about, AES, RSA, Diffie-Hellman, Elliptic curves, and all those crypto packages you're using, OpenSSL, GnuTLS, Keyczar, your operating system's crypto API, these are only computationally secure.
What's the difference? While information-theoretically secure algorithms are secure, period, those other algorithms cannot guarantee security against an adversary with unlimited computational power who's trying all possibilities for keys. We still use them because it would take all the computers in the world taken together longer than the universe has existed, so far. That's the level of “insecurity” we're talking about here.
Unless some clever guy breaks the algorithm itself, using much less computational power. Even computational power achievable today. That's the big prize every cryptanalyst dreams about: breaking AES itself, breaking RSA itself and so on.
So now we're at the point where you don't trust the inner building blocks of the random number generator, insisting on “true randomness” instead of “pseudo randomness”. But then you're using those “true” random numbers in algorithms that you so despise that you didn't want them near your random number generator in the first place!
Truth is, when state-of-the-art hash algorithms are broken, or when state-of-the-art block ciphers are broken, it doesn't matter that you get “philosophically insecure” random numbers because of them. You've got nothing left to securely use them for anyway.
So just use those computationally-secure random numbers for your computationally-secure algorithms. In other words: use /dev/urandom.
Structure of Linux's random number generator¶
An incorrect view¶
Chances are, your idea of the kernel's random number generator is something similar to this:
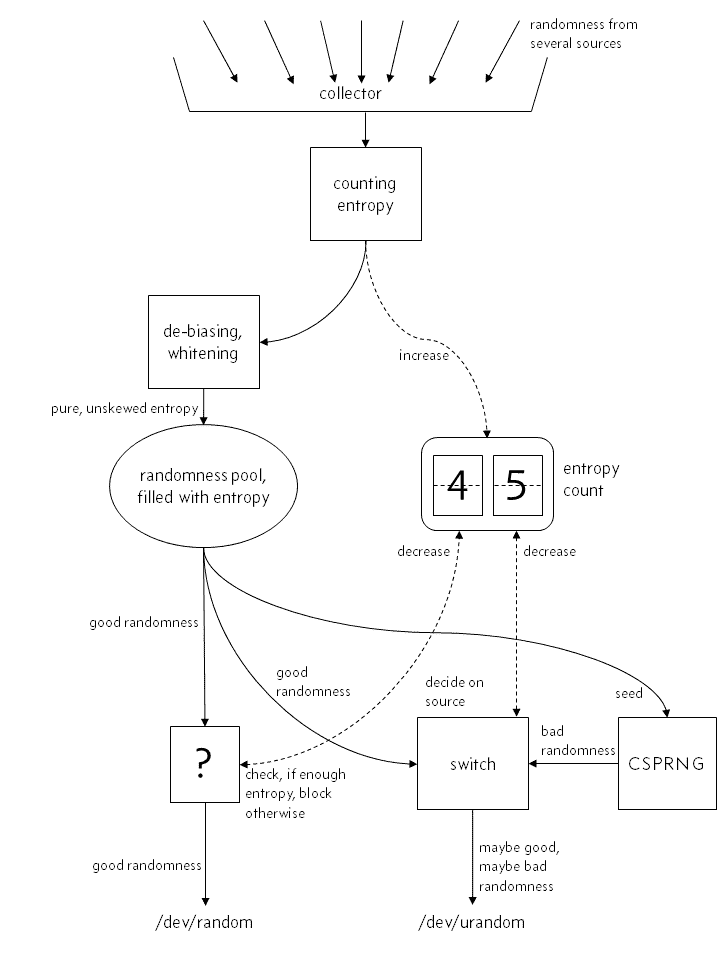
“True randomness”, albeit possibly skewed and biased, enters the system and its entropy is precisely counted and immediately added to an internal entropy counter. After de-biasing and whitening it's entering the kernel's entropy pool, where both /dev/random and /dev/urandom get their random numbers from.
The “true” random number generator, /dev/random, takes those random numbers straight out of the pool, if the entropy count is sufficient for the number of requested numbers, decreasing the entropy counter, of course. If not, it blocks until new entropy has entered the system.
The important thing in this narrative is that /dev/random basically yields the numbers that have been input by those randomness sources outside, after only the necessary whitening. Nothing more, just pure randomness.
/dev/urandom, so the story goes, is doing the same thing. Except when there isn't sufficient entropy in the system. In contrast to /dev/random, it does not block, but gets “low quality random” numbers from a pseudorandom number generator (conceded, a cryptographically secure one) that is running alongside the rest of the random number machinery. This CSPRNG is just seeded once (or maybe every now and then, it doesn't matter) with “true randomness” from the randomness pool, but you can't really trust it.
In this view, that seems to be in a lot of people's minds when they're talking about random numbers on Linux, avoiding /dev/urandom is plausible.
Because either there is enough entropy left, then you get the same you'd have gotten from /dev/random. Or there isn't, then you get those low-quality random numbers from a CSPRNG that almost never saw high-entropy input.
Devilish, right? Unfortunately, also utterly wrong. In reality, the internal structure of the random number generator looks like this.
A better simplification¶
Before Linux 4.8¶
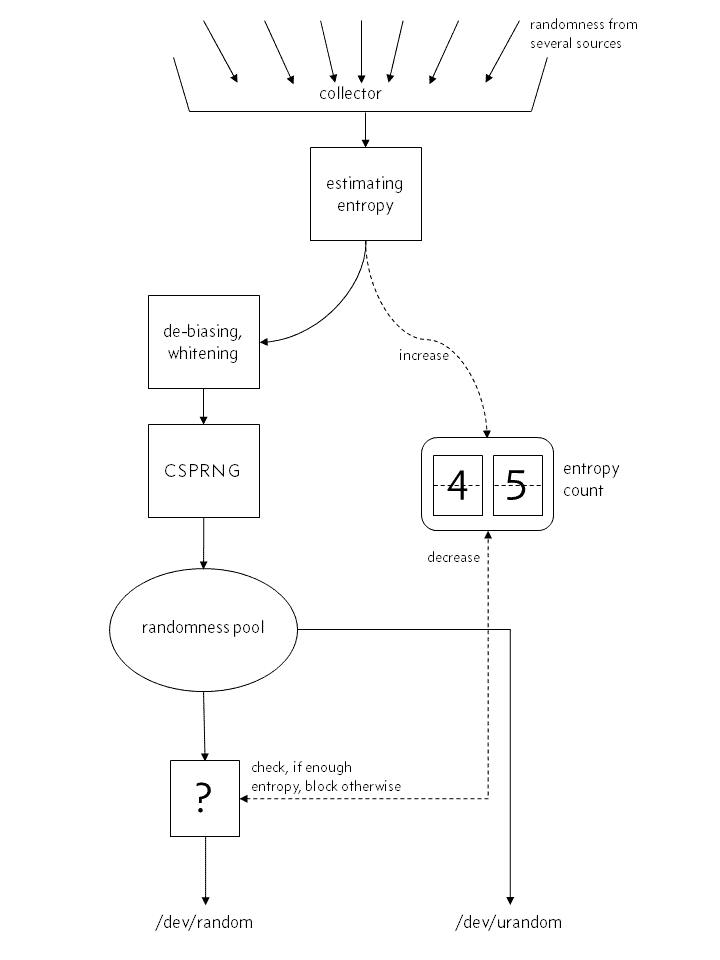
See the big difference? The CSPRNG is not running alongside the random number generator, filling in for those times when /dev/urandom wants to output something, but has nothing good to output. The CSPRNG is an integral part of the random number generation process. There is no /dev/random handing out “good and pure” random numbers straight from the whitener. Every randomness source's input is thoroughly mixed and hashed inside the CSPRNG, before it emerges as random numbers, either via /dev/urandom or /dev/random.
By the way
This is a pretty rough simplification. In fact, there isn't just one, but three pools filled with entropy. One primary pool, and one for /dev/random and /dev/urandom each, feeding off the primary pool. Those three pools all have their own entropy counts, but the counts of the secondary pools (for /dev/random and /dev/urandom) are mostly close to zero, and “fresh” entropy flows from the primary pool when needed, decreasing its entropy count. Also there is a lot of mixing and re-injecting outputs back into the system going on. All of this is far more detail than is necessary for this document.
Another important difference is that there is no entropy counting going on here, but estimation. The amount of entropy some source is giving you isn't something obvious that you just get, along with the data. It has to be estimated. Please note that when your estimate is too optimistic, the dearly held property of /dev/random, that it's only giving out as many random numbers as available entropy allows, is gone. Unfortunately, it's hard to estimate the amount of entropy.
The Linux kernel uses only the arrival times of events to estimate their entropy. It does that by interpolating polynomials of those arrival times, to calculate “how surprising” the actual arrival time was, according to the model. Whether this polynomial interpolation model is the best way to estimate entropy is an interesting question. There is also the problem that internal hardware restrictions might influence those arrival times. The sampling rates of all kinds of hardware components may also play a role, because they directly influence the values and the granularity of those event arrival times.
In the end, to the best of our knowledge, the kernel's entropy estimate is pretty good. Which means it's conservative. People argue about how good it really is, but that issue is far above my head. Still, if you insist on never handing out random numbers that are not “backed” by sufficient entropy, you might be nervous here. I'm sleeping sound because I don't care about the entropy estimate.
So to make one thing crystal clear: both /dev/random and /dev/urandom are fed by the same CSPRNG. Only the behavior when their respective pool runs out of entropy, according to some estimate, differs: /dev/random blocks, while /dev/urandom does not.
From Linux 4.8 onward¶
In Linux 4.8 the equivalency between /dev/urandom and /dev/random was given up. Now /dev/urandom output does not come from an entropy pool, but directly from a CSPRNG.
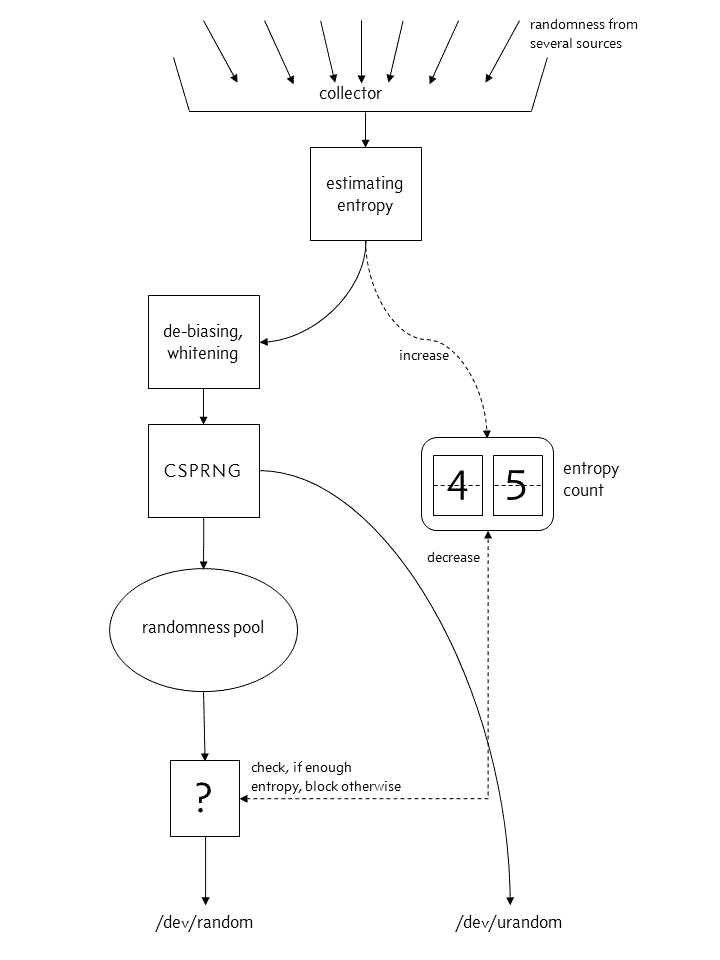
We will see shortly why that is not a security problem.
What's wrong with blocking?¶
Have you ever waited for /dev/random to give you more random numbers? Generating a PGP key inside a virtual machine maybe? Connecting to a web server that's waiting for more random numbers to create an ephemeral session key?
That's the problem. It inherently runs counter to availability. So your system is not working. It's not doing what you built it to do. Obviously, that's bad. You wouldn't have built it if you didn't need it.
But the problem runs even deeper: people don't like to be stopped in their ways. They will devise workarounds, concoct bizarre machinations to just get it running. People who don't know anything about cryptography. Normal people.
By the way
I'm working on safety-related systems in factory automation. Can you guess what the main reason for failures of safety systems is? Manipulation. Simple as that. Something about the safety measure bugged the worker. It took too much time, was too inconvenient, whatever. People are very resourceful when it comes to finding “inofficial solutions”.
Why not patching out the call to random()? Why not having some guy in a web forum tell you how to use some strange ioctl to increase the entropy counter? Why not switch off SSL altogether?
In the end you just educate your users to do foolish things that compromise your system's security without you ever knowing about it.
It's easy to disregard availability, usability or other nice properties. Security trumps everything, right? So better be inconvenient, unavailable or unusable than feign security.
But that's a false dichotomy. Blocking is not necessary for security. As we saw, /dev/urandom gives you the same kind of random numbers as /dev/random, straight out of a CSPRNG. Use it!
The CSPRNGs are alright¶
But now everything sounds really bleak. If even the high-quality random numbers from /dev/random are coming out of a CSPRNG, how can we use them for high-security purposes?
It turns out, that “looking random” is the basic requirement for a lot of our cryptographic building blocks. If you take the output of a cryptographic hash, it has to be indistinguishable from a random string so that cryptographers will accept it. If you take a block cipher, its output (without knowing the key) must also be indistinguishable from random data.
If anyone could gain an advantage over brute force breaking of cryptographic building blocks, using some perceived weakness of those CSPRNGs over “true” randomness, then it's the same old story: you don't have anything left. Block ciphers, hashes, everything is based on the same mathematical fundament as CSPRNGs. So don't be afraid.
What about entropy running low?¶
It doesn't matter.
The underlying cryptographic building blocks are designed such that an attacker cannot predict the outcome, as long as there was enough randomness (a.k.a. entropy) in the beginning. A usual lower limit for “enough” may be 256 bits. No more.
Considering that we were pretty hand-wavey about the term “entropy” in the first place, it feels right. As we saw, the kernel's random number generator cannot even precisely know the amount of entropy entering the system. Only an estimate. And whether the model that's the basis for the estimate is good enough is pretty unclear, too.
Re-seeding¶
But if entropy is so unimportant, why is fresh entropy constantly being injected into the random number generator?
First, it cannot hurt. If you've got more randomness just lying around, by all means use it!
By the way
djb remarked that more entropy actually can hurt.
There is another reason why re-seeding the random number generator every now and then is important:
Imagine an attacker knows everything about your random number generator's internal state. That's the most severe security compromise you can imagine, the attacker has full access to the system.
You've totally lost now, because the attacker can compute all future outputs from this point on.
But over time, with more and more fresh entropy being mixed into it, the internal state gets more and more random again. So that such a random number generator's design is kind of self-healing.
But this is injecting entropy into the generator's internal state, it has nothing to do with blocking its output.
The random and urandom man page¶
Update!
There has actually been an updated version of the Linux kernel man page for /dev/random and /dev/urandom. Unfortunately, a simple web search still turns up the old, deficient version I'm describing here in the top results. Furthermore, many Linux distributions still ship the old man pages. So unfortunately this section needs to stay a bit longer in the essay. I'm so looking forward to deleting it!
The man page for /dev/random and /dev/urandom is pretty effective when it comes to instilling fear into the gullible programmer's mind:
Quote
A read from the /dev/urandom device will not block waiting for more entropy. As a result, if there is not sufficient entropy in the entropy pool, the returned values are theoretically vulnerable to a cryptographic attack on the algorithms used by the driver. Knowledge of how to do this is not available in the current unclassified literature, but it is theoretically possible that such an attack may exist. If this is a concern in your application, use /dev/random instead.
Such an attack is not known in “unclassified literature”, but the NSA certainly has one in store, right? And if you're really concerned about this (you should!), please use /dev/random, and all your problems are solved.
The truth is, while there may be such an attack available to secret services, evil hackers or the Bogeyman, it's just not rational to just take it as a given.
And even if you need that peace of mind, let me tell you a secret: no practical attacks on AES, SHA-3 or other solid ciphers and hashes are known in the “unclassified” literature, either. Are you going to stop using those, as well? Of course not!
Now the fun part: “use /dev/random instead”. While /dev/urandom does not block, its random number output comes from the very same CSPRNG as /dev/random's.
If you really need information-theoretically secure random numbers (you don't!), and that's about the only reason why the entropy of the CSPRNG's input matters, you can't use /dev/random, either!
The man page is silly, that's all. At least it tries to redeem itself with this:
Quote
If you are unsure about whether you should use /dev/random or /dev/urandom, then probably you want to use the latter. As a general rule, /dev/urandom should be used for everything except long-lived GPG/SSL/SSH keys.
By the way
The current, updated version of the man page says in no uncertain terms: The /dev/random interface is considered a legacy interface, and /dev/urandom is preferred and sufficient in all use cases, with the exception of applications which require randomness during early boot time; for these applications, getrandom(2) must be used instead, because it will block until the entropy pool is initialized.
Fine. I think it's unnecessary, but if you want to use /dev/random for your “long-lived keys”, by all means, do so! You'll be waiting a few seconds typing stuff on your keyboard, that's no problem.
But please don't make connections to a mail server hang forever, just because you “wanted to be safe”.
Orthodoxy¶
The view espoused here is certainly a tiny minority's opinions on the Internet. But ask a real cryptographer, you'll be hard pressed to find someone who sympathizes much with that blocking /dev/random.
Let's take Daniel Bernstein, better known as djb:
Quote
Cryptographers are certainly not responsible for this superstitious nonsense. Think about this for a moment: whoever wrote the /dev/random manual page seems to simultaneously believe that
(1) we can't figure out how to deterministically expand one 256-bit /dev/random output into an endless stream of unpredictable keys (this is what we need from urandom), but
(2) we can figure out how to use a single key to safely encrypt many messages (this is what we need from SSL, PGP, etc.).
For a cryptographer this doesn't even pass the laugh test.
Or Thomas Pornin, who is probably one of the most helpful persons I've ever encountered on the Stackexchange sites:
Quote
The short answer is yes. The long answer is also yes. /dev/urandom yields data which is indistinguishable from true randomness, given existing technology. Getting “better” randomness than what /dev/urandom provides is meaningless, unless you are using one of the few "information theoretic" cryptographic algorithm, which is not your case (you would know it).
The man page for urandom is somewhat misleading, arguably downright wrong, when it suggests that /dev/urandom may "run out of entropy" and /dev/random should be preferred;
Or maybe Thomas Ptacek, who is not a real cryptographer in the sense of designing cryptographic algorithms or building cryptographic systems, but still the founder of a well-reputed security consultancy that's doing a lot of penetration testing and breaking bad cryptography:
Quote
Use urandom. Use urandom. Use urandom. Use urandom. Use urandom. Use urandom.
Not everything is perfect¶
/dev/urandom isn't perfect. The problems are twofold:
On Linux, unlike FreeBSD, /dev/urandom never blocks. Remember that the whole security rested on some starting randomness, a seed?
Linux's /dev/urandom happily gives you not-so-random numbers before the kernel even had the chance to gather entropy. When is that? At system start, booting the computer.
FreeBSD does the right thing: they don't have the distinction between /dev/random and /dev/urandom, both are the same device. At startup /dev/random blocks once until enough starting entropy has been gathered. Then it won't block ever again.
On Linux it isn't too bad, because Linux distributions save some random numbers when booting up the system (but after they have gathered some entropy, since the startup script doesn't run immediately after switching on the machine) into a seed file that is read next time the machine is booting. So you carry over the randomness from the last running of the machine.
Obviously that isn't as good as if you let the shutdown scripts write out the seed, because in that case there would have been much more time to gather entropy. The advantage is obviously that this does not depend on a proper shutdown with execution of the shutdown scripts (in case the computer crashes, for example).
And it doesn't help you the very first time a machine is running, but the Linux distributions usually do the same saving into a seed file when running the installer. So that's mostly okay.
Virtual machines are the other problem. Because people like to clone them, or rewind them to a previously saved check point, this seed file doesn't help you.
But the solution still isn't using /dev/random everywhere, but properly seeding each and every virtual machine after cloning, restoring a checkpoint, whatever.
Update!
In the meantime, Linux has implemented a new syscall, originally introduced by OpenBSD as getentropy(2): getrandom(2). This syscall does the right thing: blocking until it has gathered enough initial entropy, and never blocking after that point. Of course, it is a syscall, not a character device, so it isn't as easily accessible from shell or script languages. It is available from Linux 3.17 onward.
tldr;¶
Just use /dev/urandom!